The history of artificial intelligence often appears as a series of breakthroughs followed by periods of disappointment. But when viewed from a distance, a simpler pattern emerges: meaningful progress tends to occur when a dominant bottleneck is removed. Early AI systems relied on explicitly coded rules and expert knowledge. They performed well in narrow, controlled settings, but struggled when exposed to real-world complexity. The limitation was not ambition or intelligence, but scale: human knowledge could not be fully articulated, maintained, or updated through rules alone. Statistical machine learning shifted the burden from rules to data. Instead of telling systems what to do, engineers allowed models to learn patterns from examples. Yet progress remained limited until data volumes and computational power became widely available. When large datasets and scalable computing infrastructure emerged, deep learning did not advance gradually, it accelerated rapidly.
This cycle has repeated for decades. Each time progress seemed to plateau, it was not because the field had reached its limits, but because a hidden constraint had become dominant. Today, models are larger than ever, data is abundant, and computing power is widely accessible. Yet in many real-world applications, improvements are again becoming incremental. Historically, this pattern signals not the end of progress, but the emergence of a new bottleneck.
.jpg)
As deep learning matured, attention initially focused on improving models: deeper architectures, new training methods, and better optimization. Over time, many organizations reached a practical conclusion: improving the data often had more impact than changing the model. This insight led to the rise of data-centric AI: focusing on data quality, labeling consistency, coverage, and relevance. This shift was important. It acknowledged that intelligence does not emerge from algorithms alone, but from the interaction between models and the information they receive. However, most data-centric approaches still treat data as raw material: images, signals, text, rather than as information shaped by physical, mathematical, or operational structure.
At this point, a deeper inefficiency becomes visible. Many modern AI systems are trained end-to-end on raw inputs and asked to learn everything simultaneously: noise suppression, structure, constraints, and decision logic. In practice, this means models often spend significant effort rediscovering patterns that scientists and engineers already understand, geometry, system dynamics, conservation laws, or operational limits. We often assume that with enough data and training, models will eventually “figure this out.” Sometimes they do. Sometimes they do not. And even when they do, the process can be inefficient, expensive, and difficult to explain. Finite datasets do not automatically reveal all governing principles, and training longer does not change the nature of the problem, it only increases cost. Seen this way, the emerging bottleneck is not the lack of data or compute, but the inefficiency of asking learning systems to relearn the world from scratch.
A useful way to think about intelligent systems is that learning should focus on what is uncertain, not on what is already known. Or, as the idea is often summarized:
This principle already exists in modern AI practice. Today’s large models are typically trained on massive datasets and then fine-tuned for specific tasks. Fine-tuning works because knowledge learned in one context can be transferred to another. But this raises a deeper question: if we are willing to inject knowledge after training, why not embed certain forms of knowledge before or during training as well? Physics, mathematics, and engineering principles are not heuristics or opinions, they are stable descriptions of how systems behave. Encoding them explicitly does not limit learning; it focuses it. Consider a simple analogy. Two teams analyze the same complex problem. One examines raw, unstructured information and hopes patterns emerge over time. The other first organizes the problem using known constraints, relationships, and principles. Both teams are capable, but the second reaches clarity faster. The difference is not intelligence — it is framing.
Across both research and industry, this idea appears repeatedly. Signal processing transforms raw measurements into meaningful representations. Physics-informed neural networks constrain models using known laws. Symmetry-aware and constraint-based approaches reduce the space that learning must explore. In all these cases, mathematics and engineering are not competing with AI, they are guiding it. These practices improve data efficiency, reduce training time and energy consumption, and lead to more robust behavior when conditions change. They also improve interpretability, because intermediate representations correspond to real-world meaning rather than opaque internal states. These qualities matter most in real systems: edge devices, infrastructure, energy, sustainability, and safety-critical applications. In many organizations today, however, there is a growing separation between domain experts and data scientists. Domain experts carry deep scientific and engineering understanding, while data scientists are trained to apply powerful learning tools quickly. Too often, these groups work in parallel rather than together.
Engineering disciplines are not legacy knowledge. They are compressed understanding of how the world works. As AI systems move from demonstrations to dependable products, the most effective designs are rarely purely end-to-end or purely handcrafted. They are hybrid by necessity: explicit knowledge where it exists, learning where uncertainty remains.
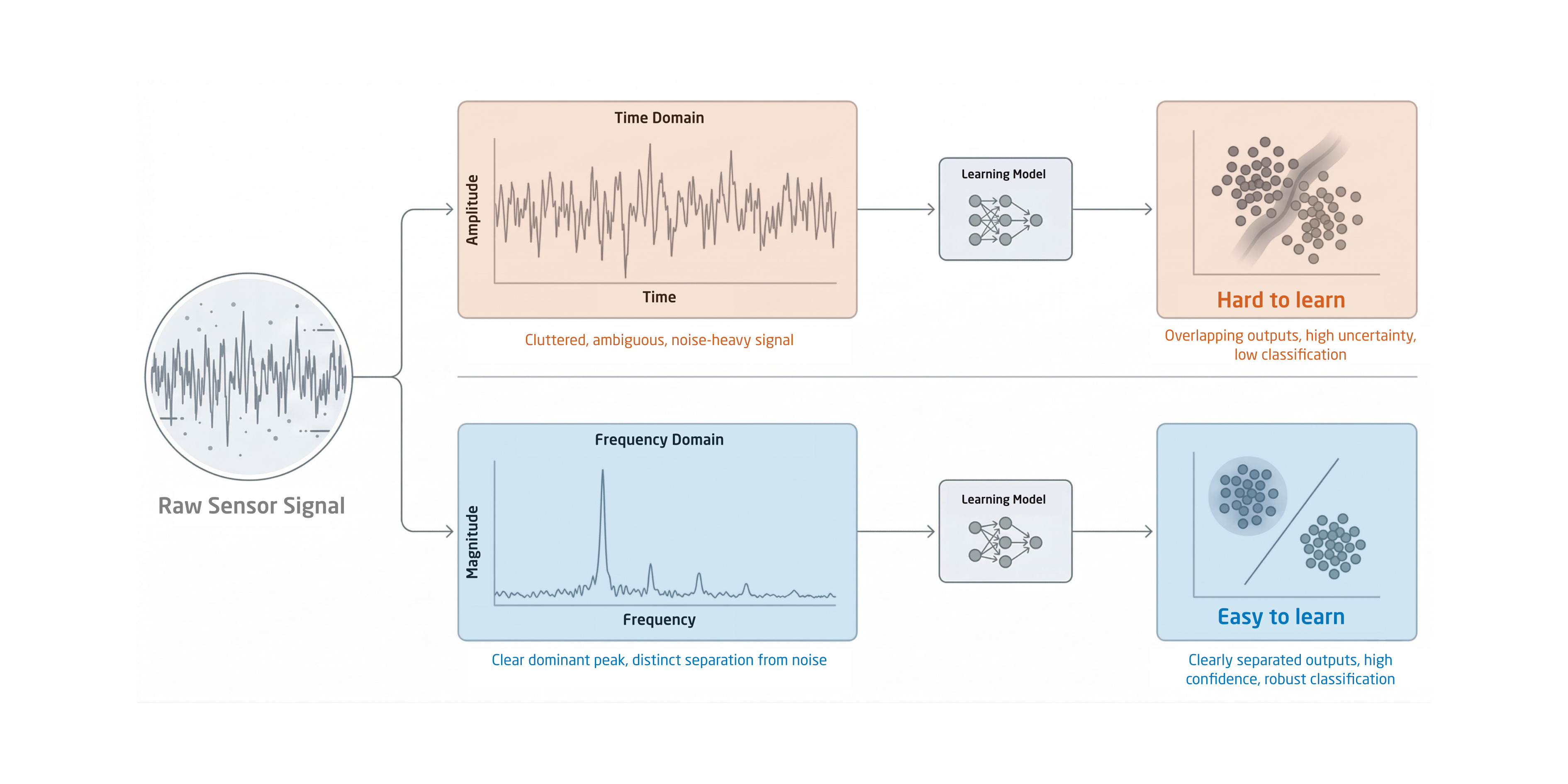
Every major leap in AI has followed a shift in how problems are framed. Today, that shift is not simply toward larger models or more data, but toward using what we already know more wisely. AI does not replace science and engineering. It succeeds because of them.
.png)


