إذا نظرنا إلى تاريخ الذكاء الاصطناعي، فقد يبدو وكأنه موجات من الإنجازات تتبعها فترات من التعثر أو خيبة الأمل. لكن عند التأمل فيه بصورة أشمل، يظهر لنا معنى أوضح: التقدّم الحقيقي غالبًا لا يحدث لأننا أصبحنا “أذكى”، بل لأن عقبة أساسية كانت تعيق التطور قد أُزيلت. في بدايات الذكاء الاصطناعي، كانت الأنظمة تعتمد على قواعد مكتوبة يدويًا وعلى خبرة البشر المباشرة. وقد نجحت هذه الأنظمة في البيئات المحدودة والواضحة، لكنها كانت تضعف كلما اقتربت من تعقيد الواقع. ولم تكن المشكلة في نقص الذكاء أو ضعف الفكرة، بل في أن المعرفة البشرية أوسع وأكثر تعقيدًا من أن تُختصر كلها في مجموعة قواعد ثابتة. ثم انتقل المجال إلى التعلّم الآلي الإحصائي، فأصبح الاعتماد أقل على القواعد وأكثر على البيانات. وبدل أن نخبر الآلة بما يجب أن تفعله خطوة بخطوة، بدأنا نزوّدها بأمثلة لتتعلم منها الأنماط بنفسها. لكن هذا التحول لم يُحدث طفرة كبيرة فورًا، لأن البيانات الضخمة والقدرة الحاسوبية لم تكونا متاحتين بعد بالشكل الكافي. وعندما توفرت كميات هائلة من البيانات، وظهرت بنى حاسوبية قادرة على التدريب على نطاق واسع، انطلق التعلّم العميق بقوة. لم يكن التقدم عندها بطيئًا أو تدريجيًا، بل كان سريعًا وواضحًا.
وهذا النمط تكرر أكثر من مرة عبر العقود. ففي كل مرة ظن الناس أن المجال بلغ حدوده، كان السبب الحقيقي غالبًا هو ظهور قيد جديد لم يكن واضحًا من قبل. واليوم لدينا نماذج ضخمة، وبيانات وفيرة، وقدرات حاسوبية كبيرة، ومع ذلك نرى أن التحسن في كثير من التطبيقات الواقعية أصبح أبطأ وأكثر محدودية. وهذا، تاريخيًا، لا يعني أن التقدم انتهى، بل يعني أن هناك عقبة جديدة بدأت تظهر وتفرض نفسها.
.jpg)
مع تطور التعلّم العميق، انشغل الباحثون في البداية بتحسين النماذج نفسها: جعلها أعمق، وتطوير طرق التدريب، وتحسين الخوارزميات. لكن مع الوقت، بدأت كثير من الجهات تصل إلى ملاحظة عملية مهمة: في كثير من الأحيان، تحسين البيانات نفسها يكون أثره أكبر من تغيير النموذج. ومن هنا ظهر ما يُعرف بالذكاء الاصطناعي المتمحور حول البيانات، أي التركيز على جودة البيانات، وصحة التوسيم، وشمولية التغطية، وملاءمة البيانات للمشكلة. كان هذا التحول مهمًا، لأنه ذكّرنا بأن الذكاء لا يولد من الخوارزمية وحدها، بل من العلاقة بين النموذج وبين نوعية المعلومات التي تُقدَّم له. ومع ذلك، بقيت هناك مشكلة أعمق: كثير من هذه المقاربات ما زالت تتعامل مع البيانات على أنها مجرد مادة خام، لا على أنها شيء له بنية ومعنى وسياق تحكمه قوانين ومبادئ معروفة.
وهنا يظهر وجه جديد للمشكلة. فالكثير من أنظمة الذكاء الاصطناعي الحديثة تُدرَّب على مدخلات خام، ويُطلب منها أن تتعلم كل شيء دفعة واحدة: أن تزيل الضوضاء، وتكتشف الأنماط، وتفهم القيود، وتتعلم منطق القرار. وكأننا نطلب منها أن تعيد اكتشاف ما يعرفه العلماء والمهندسون أصلًا عن طبيعة الأنظمة، وحركتها، وحدودها، وقوانينها. وغالبًا ما نفترض أن النموذج، إذا أعطيناه بيانات أكثر ووقت تدريب أطول، فسيصل في النهاية إلى الفهم المطلوب. وهذا قد يحدث أحيانًا، لكنه ليس مضمونًا دائمًا. وحتى عندما يحدث، قد يكون الطريق طويلًا ومكلفًا وصعب التفسير. فالإكثار من البيانات لا يعني بالضرورة الوصول إلى كل القوانين الحاكمة، وإطالة التدريب لا تغيّر طبيعة المشكلة نفسها، بل قد تزيد الكلفة فقط. ومن هذا المنطلق، يمكن القول إن المشكلة الجديدة لم تعد نقص البيانات أو ضعف القدرة الحاسوبية، بل أصبحت في عدم كفاءة جعل النماذج تبدأ من الصفر في أشياء نعرفها نحن مسبقًا.
من الأفضل أن ننظر إلى الأنظمة الذكية بهذه الطريقة: التعلّم ينبغي أن يركّز على المجهول، لا على الأمور المحسومة والمعروفة سلفًا. أو بتعبير أبسط:
وهذا المعنى موجود أصلًا في الممارسة الحديثة للذكاء الاصطناعي. فالنماذج الكبيرة تُدرَّب أولًا على كمّ ضخم من البيانات، ثم تُعدَّل أو تُضبط لاحقًا لتناسب مهامًا محددة. ونجاح هذه العملية قائم على أن المعرفة المكتسبة في سياق ما يمكن نقلها إلى سياق آخر. وهذا يفتح بابًا مهمًا للتساؤل: إذا كنا نقبل إدخال المعرفة بعد التدريب، فلماذا لا نستفيد من بعض أنواع المعرفة قبل التدريب أو أثناءه؟ الفيزياء، والرياضيات، والهندسة ليست مجرد آراء أو تخمينات، بل هي وصف مستقر لكيفية عمل الأنظمة. ولذلك فإن تضمين هذه المبادئ داخل عملية التعلّم لا يقيّد النموذج، بل يرشده ويوجّه جهده إلى المكان الصحيح. ولتقريب الفكرة بصورة أوضح: تخيّل شخصين يريدان الوصول إلى مدينة بعيدة. أحدهما يدخل الصحراء بلا خريطة ويقول: سأبحث حتى أصل. والآخر ينطلق ومعه خريطة ومعالم واضحة للطريق. كلاهما قادر على الوصول، لكن الثاني أوفر جهدًا وأسرع وأقل عرضة للضياع. الفرق هنا ليس في الذكاء، بل في وجود معرفة سابقة تهدي الطريق. وهذا هو المقصود:
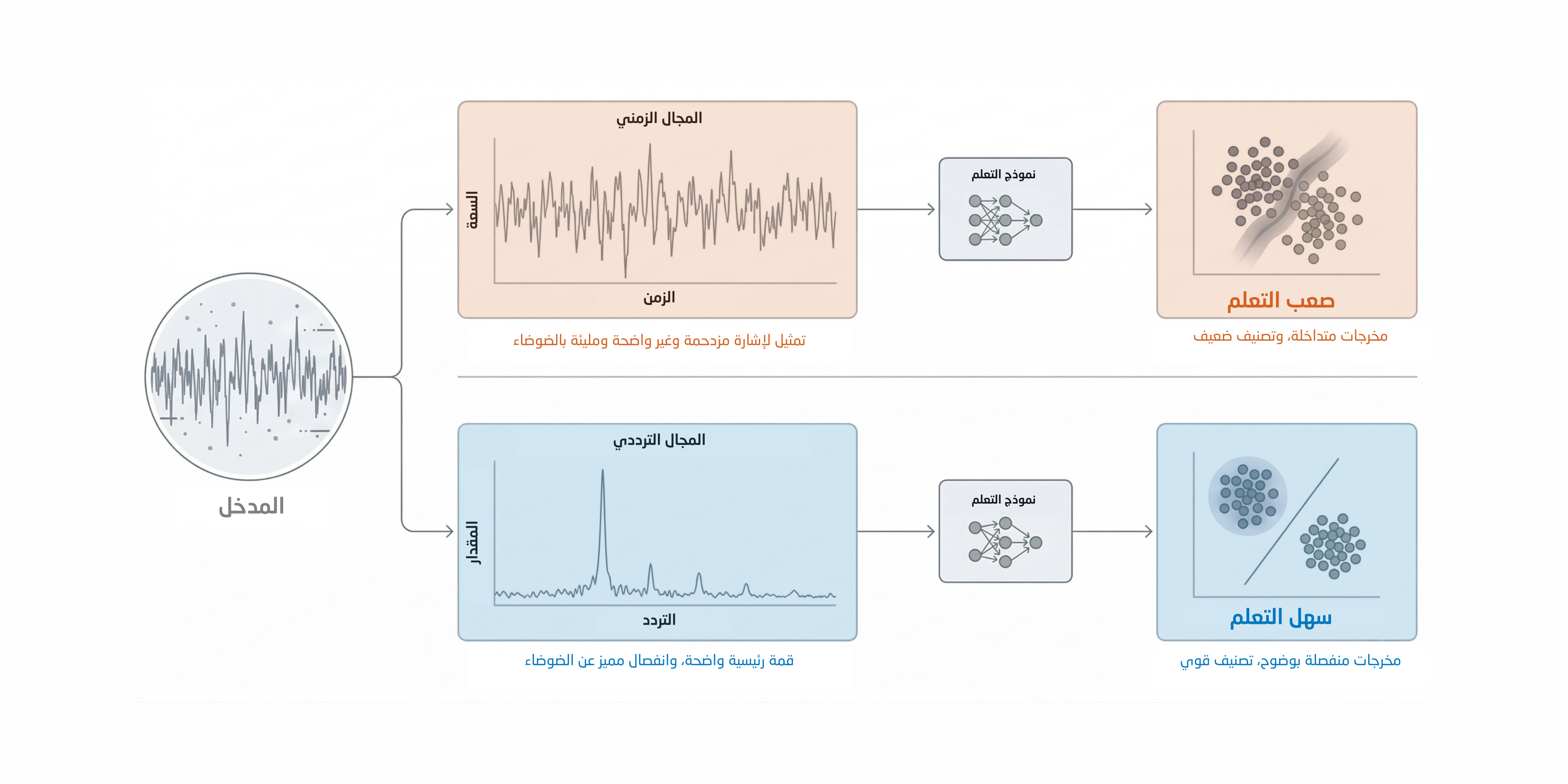
ولهذا نرى هذه الفكرة تتكرر في مجالات كثيرة. ففي معالجة الإشارات، لا نكتفي بالإشارة الخام، بل نحوّلها إلى تمثيل أوضح وأكثر معنى. وفي بعض النماذج الحديثة، تُستخدم القوانين الفيزيائية المعروفة لتقييد التعلّم ومنعه من الذهاب في اتجاهات غير منطقية. وهناك أساليب أخرى تعتمد على التناظر أو القيود الرياضية لتقليص مساحة الاحتمالات التي يجب على النموذج أن يجرّبها. في كل هذه الأمثلة، لا تكون الرياضيات والهندسة بديلًا عن الذكاء الاصطناعي، بل تكون وسيلة لتوجيهه حتى يعمل بكفاءة أعلى. وهذا ينعكس على أمور عملية مهمة: تصبح الحاجة إلى البيانات أقل، ووقت التدريب أقصر، واستهلاك الطاقة أخف، كما يتحسن أداء النظام عند تغير الظروف. كذلك تصبح النتائج أوضح وأسهل في التفسير، لأن المراحل الوسيطة في المعالجة تكون مرتبطة بمعانٍ حقيقية في العالم، لا بمجرد حالات داخلية غامضة. وتزداد أهمية هذا الأمر في التطبيقات الواقعية الحساسة، مثل الحوسبة الطرفية، والطاقة، والاستدامة، والأنظمة التي ترتبط بالسلامة والاعتمادية. لكن في المقابل، هناك مشكلة متزايدة في كثير من المؤسسات اليوم: خبراء المجال يملكون الفهم العلمي والهندسي العميق، وعلماء البيانات يملكون أدوات التعلّم الحديثة، غير أن الفريقين كثيرًا ما يعملان كلٌّ في مساره، بدل أن يندمجا في عمل واحد متكامل.
فالهندسة والعلوم ليست معارف قديمة تجاوزها الزمن، بل هي خلاصة مركّزة لفهمنا لكيفية عمل العالم. ومع انتقال الذكاء الاصطناعي من العروض والتجارب إلى منتجات حقيقية يمكن الاعتماد عليها، يصبح من الواضح أن أفضل الحلول ليست تلك التي تعتمد كليًا على التعلم من البداية إلى النهاية، ولا تلك التي تعتمد فقط على البناء اليدوي التقليدي، بل الحلول الهجينة التي تضع المعرفة الصريحة حيثما كانت متاحة، وتترك للتعلّم مهمة التعامل مع المساحات التي ما زالت غير مؤكدة أو غير مفهومة بالكامل.
كل قفزة كبرى في الذكاء الاصطناعي جاءت بعد تغيير في طريقة فهم المشكلة وصياغتها. واليوم، لا يتمثل هذا التغيير فقط في بناء نماذج أكبر أو جمع بيانات أكثر، بل في أن نحسن استخدام ما نعرفه أصلًا. فالذكاء الاصطناعي لا ينجح لأنه بديل عن العلم والهندسة، بل ينجح حين يبني عليهما ويستفيد منهما.
.png)


